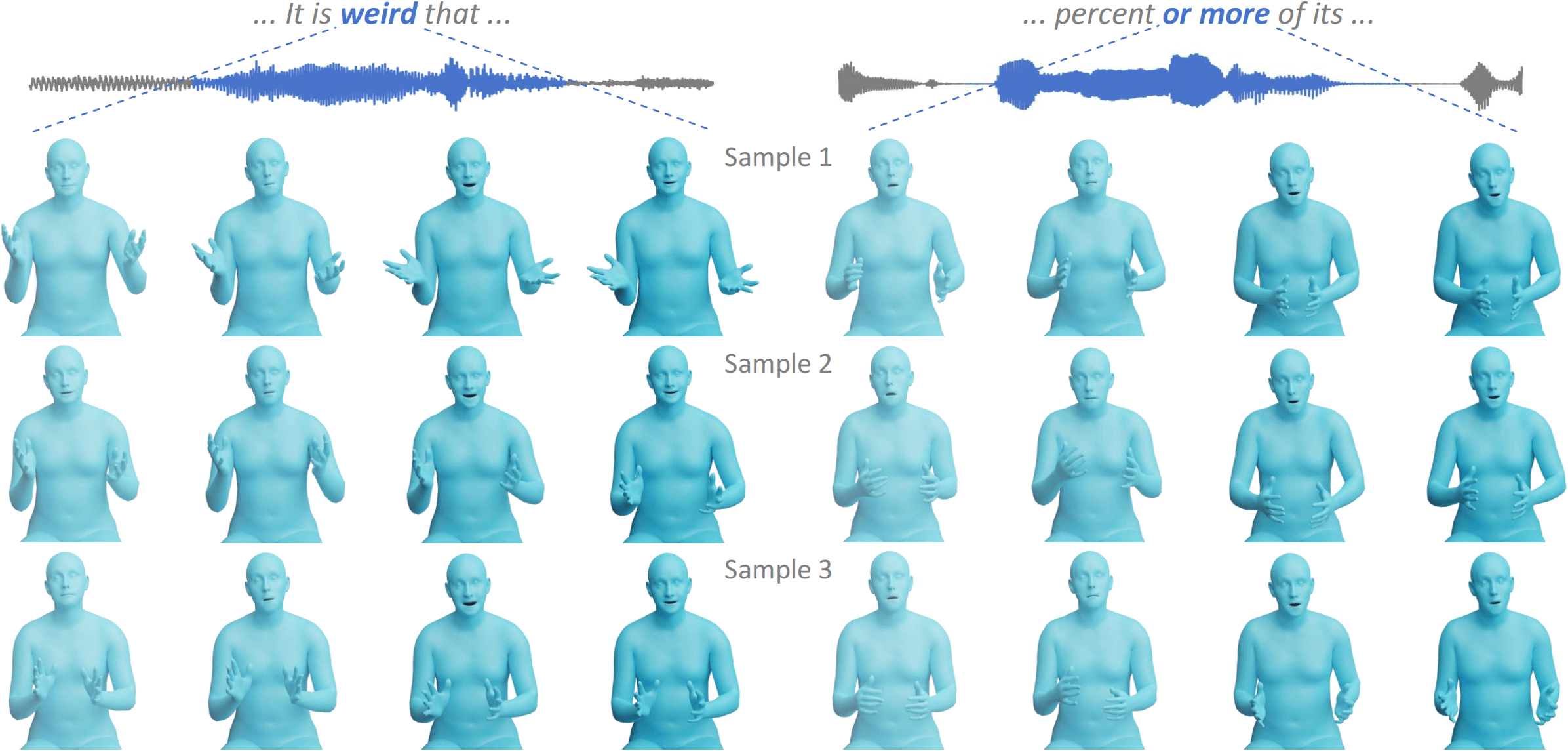
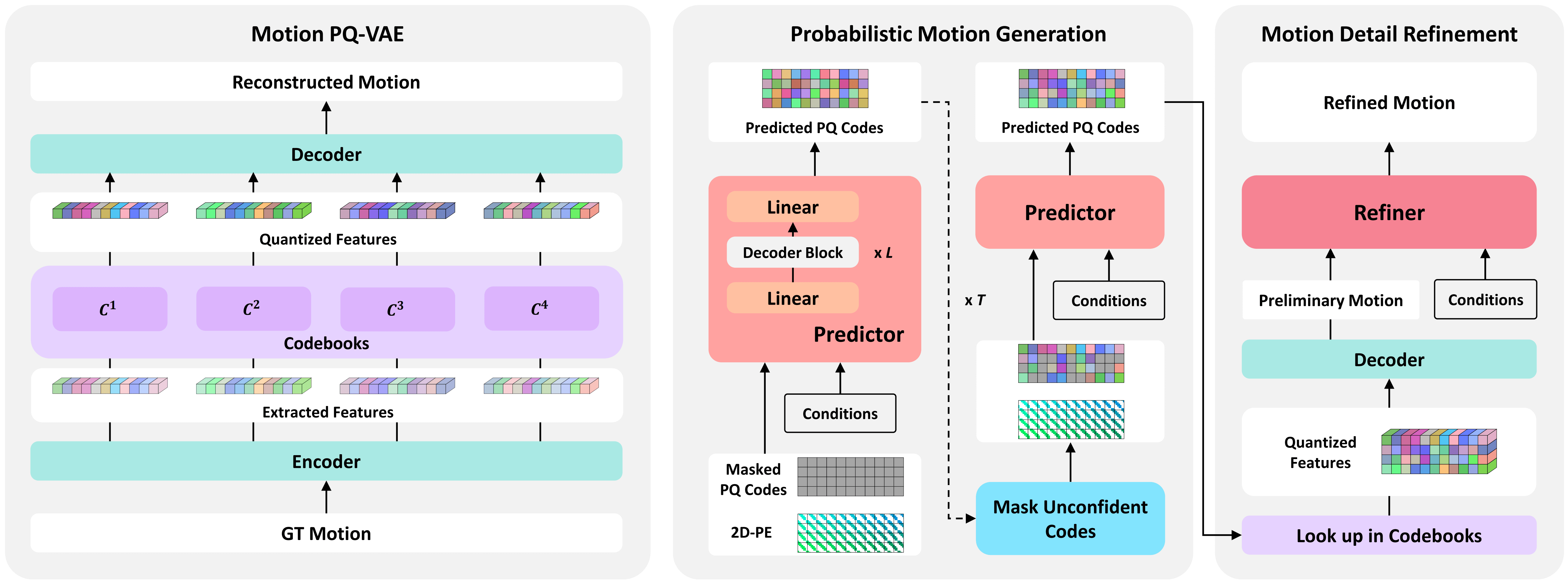
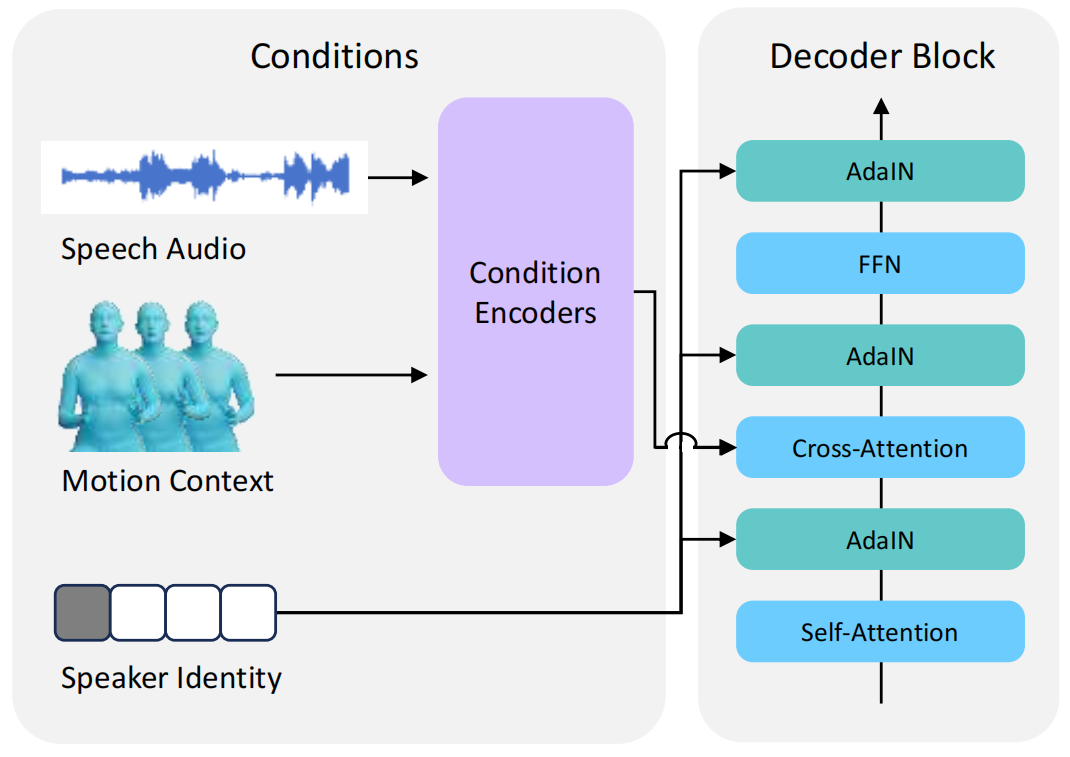
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism.
We thank Hongwei Yi for the insightful discussions, Hualin Liang for helping us conduct user study. This work was partially supported by the Major Science and Technology Innovation 2030 ``New Generation Artificial Intelligence” key project (No. 2021ZD0111700), the National Natural Science Foundation of China under Grant 62076101, Guangdong Basic and Applied Basic Research Foundation under Grant 2023A1515010007, the Guangdong Provincial Key Laboratory of Human Digital Twin under Grant 2022B1212010004, and the TCL Young Scholars Program.
@article{liu2024towards,
title={Towards Variable and Coordinated Holistic Co-Speech Motion Generation},
author={Liu, Yifei and Cao, Qiong and Wen, Yandong and Jiang, Huaiguang and Ding, Changxing},
journal={arXiv preprint arXiv:2404.00368},
year={2024}}@inproceedings{yi2023generating,
title={Generating Holistic 3D Human Motion from Speech},
author={Yi, Hongwei and Liang, Hualin and Liu, Yifei and Cao, Qiong and Wen, Yandong and Bolkart, Timo and Tao, Dacheng and Black, Michael J},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
pages={469-480},
month={June},
year={2023}
}